Jenkins Infra upgrade
Introduction
In the article Jenkins Jobs for KubeVirt Lab Validation, we covered how Jenkins did get the information about the labs and jobs to perform from the KubeVirt repositories.
In this article, we’ll cover the configuration changes in both Jenkins and the JenkinsFiles required to get our CI setup updated to latest versions and syntax .
Jenkins
Our Jenkins instance, is running on top of CentOS OpenShift and is one of the OS-enhanced Jenkins instances, that provide persistent storage and other pieces bundled, required for non-testing setups.
What we found is that Jenkins was already complaining because of pending updates (security, engine, etc), but the jenkins.war was embedded in the container image we were using.
Initial attempts tried to use environment variables to override the WAR to use, but our image was not prepared for it, so we were given the option to just generate a new container for it, but this seemed a bad approach as our image, also contained custom libraries (contra-lib) that enables communicating with OpenShift to run the tests inside containers there.
During the investigation and testing, we found that the persistent storage folder we were using (/var/lib/jenkins) contained a war folder which contained the unarchived jenkins.war, so the next attempt was to manually download the latest jenkins.war, and unzip it on that folder, which finally allowed us to upgrade Jenkins core.
The plugins
After upgrading the Jenkins core, we could use the internal plugin manager to upgrade all the remaining plugins, however, that meant a big change in the plugins, configurations, etc.
After initially being able to run the lab validations for a while, on next morning we wanted to release a new image (from Cloud-Image-Builder) and it failed to build because of the external libraries, and also affected the lab validations again, so we got back to square one for the upgrade process, leaving us with the decision to go forward with the full upgrade: the latest stable jenkins and available plugins and reconfigure what was changed to suit the upgraded requirements.
Here we’ll show you the configuration settings for each one of the new/updated plugins.
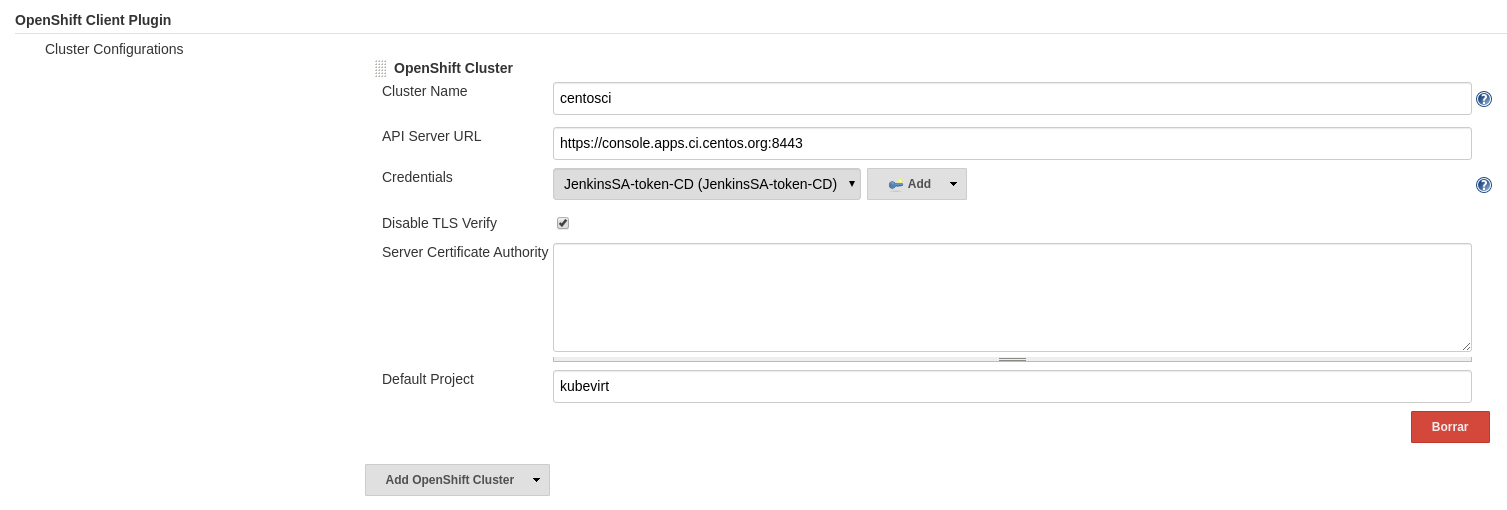
OpenShift Plugin
Updated to configure the instance of CentOS OpenShift with the system account for accessing it:
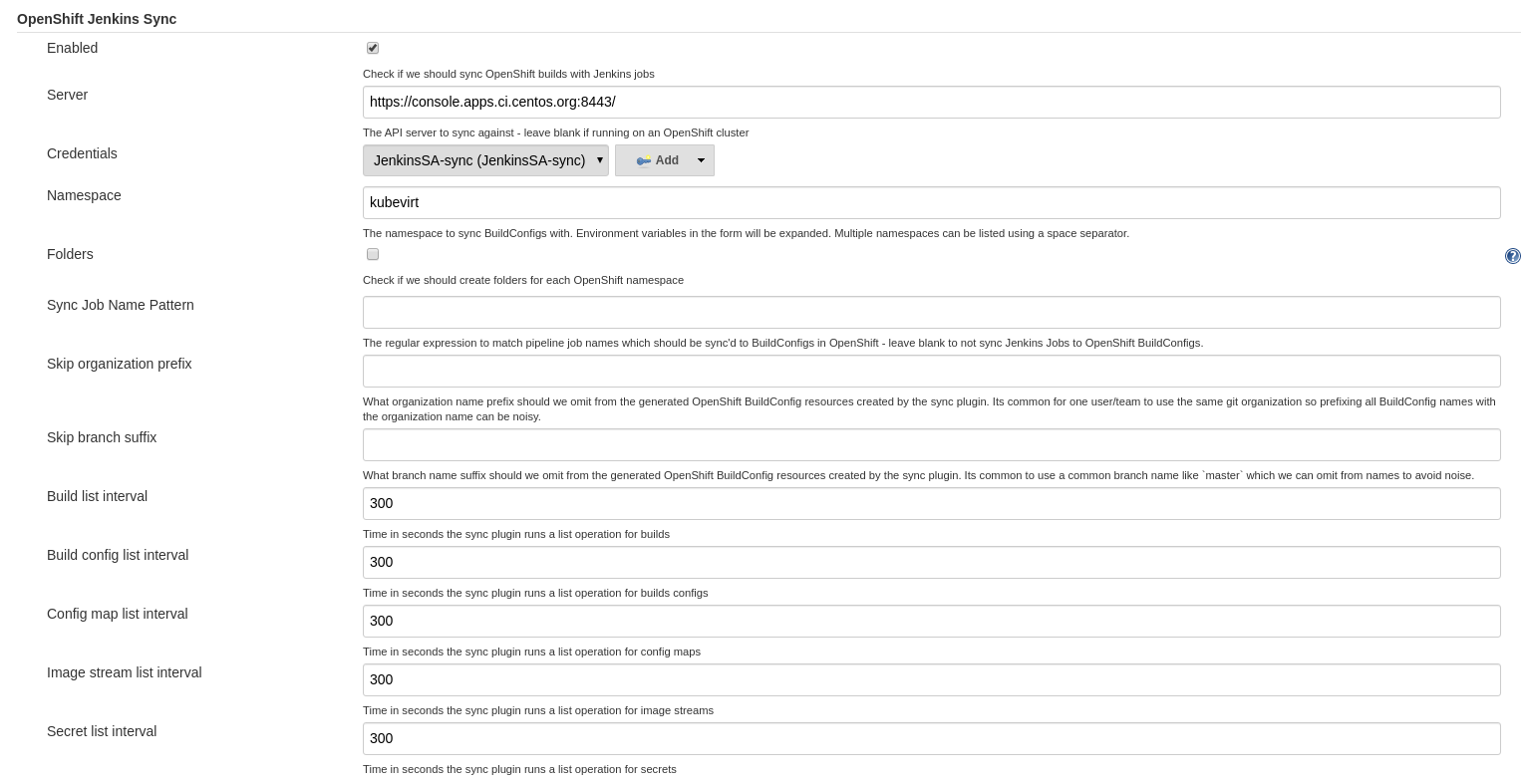
OpenShift Jenkins Sync
Updated and configured to use the console as well with kubevirt namespace:
Global Pipeline Libraries
Here we added the libraries we used, but instead of a specific commit, targetting the master branch.
- contra-lib: https://github.com/openshift/contra-lib.git
- cico-pipeline-library: https://github.com/CentOS/cico-pipeline-library.git
- contra-library: https://github.com/CentOS-PaaS-SIG/contra-env-sample-project
For all of them, we ticked:
Load ImplicitlyAllow default version to be overridenInclude @Library changes in job recent changes
Jenkins replied with the ‘currently maps to revision: hash’ for each one of them, after having loaded them properly, indicating that it was successful.
Slack plugin
In addition to regular plugins used for builds, we incorporated the slack plugin to validate the notifications of build status to a test slack channel. Configuration is really easy, from within Slack, when added the jenkins notifications plugin, a token is provided that must be configured in Jenkins as well as a default room to send notifications to.
This allows us to get notified when a new build is started and the resulting status, just in case something was generated with errors or something external changed (remember that we use latest KubeVirt release, latest tools for virtctl, kubectl and a new image is generated out of them to validate the labs).
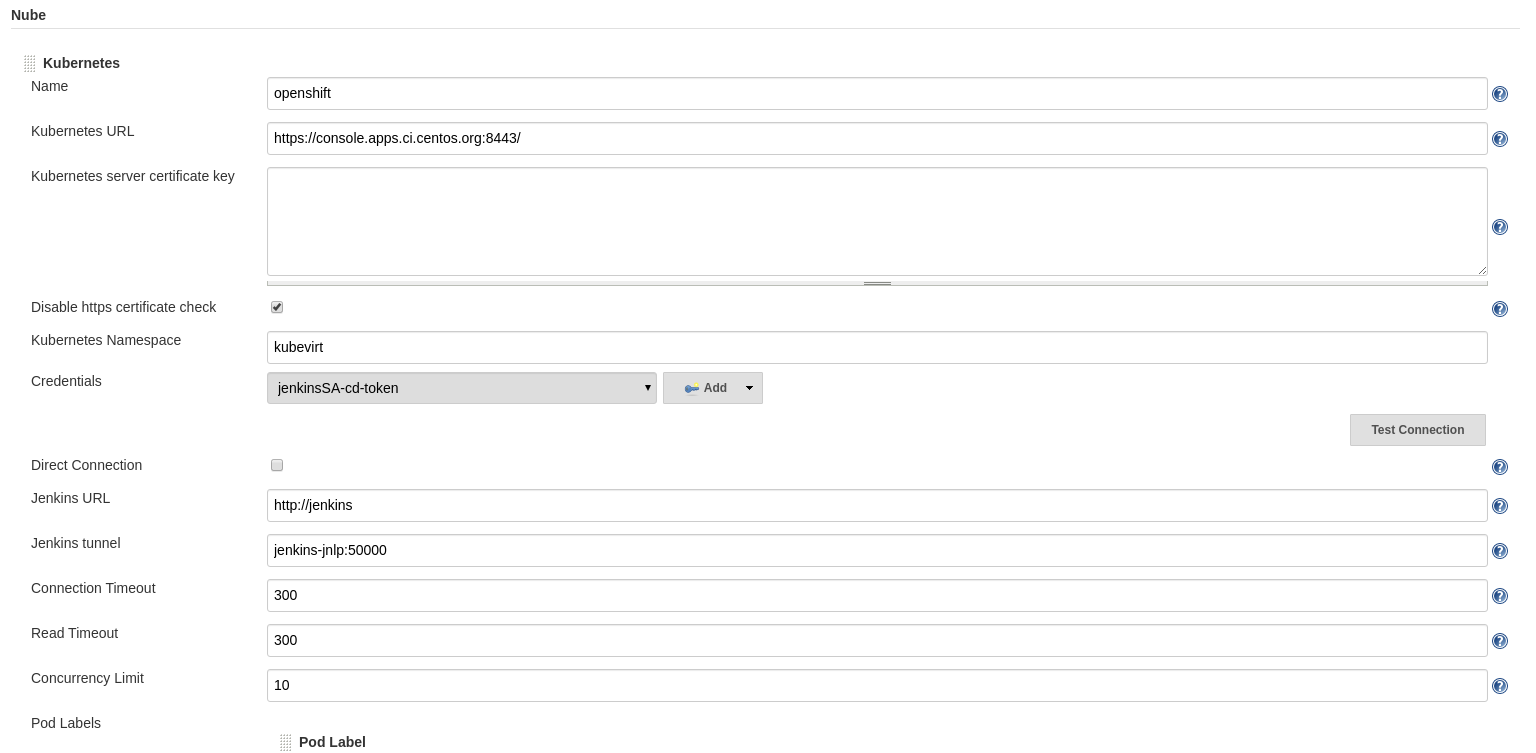
Kubernetes ‘Cloud’
In addition, Kubernets Cloud was configured pointing to the same console access and using the kubevirt namespace:
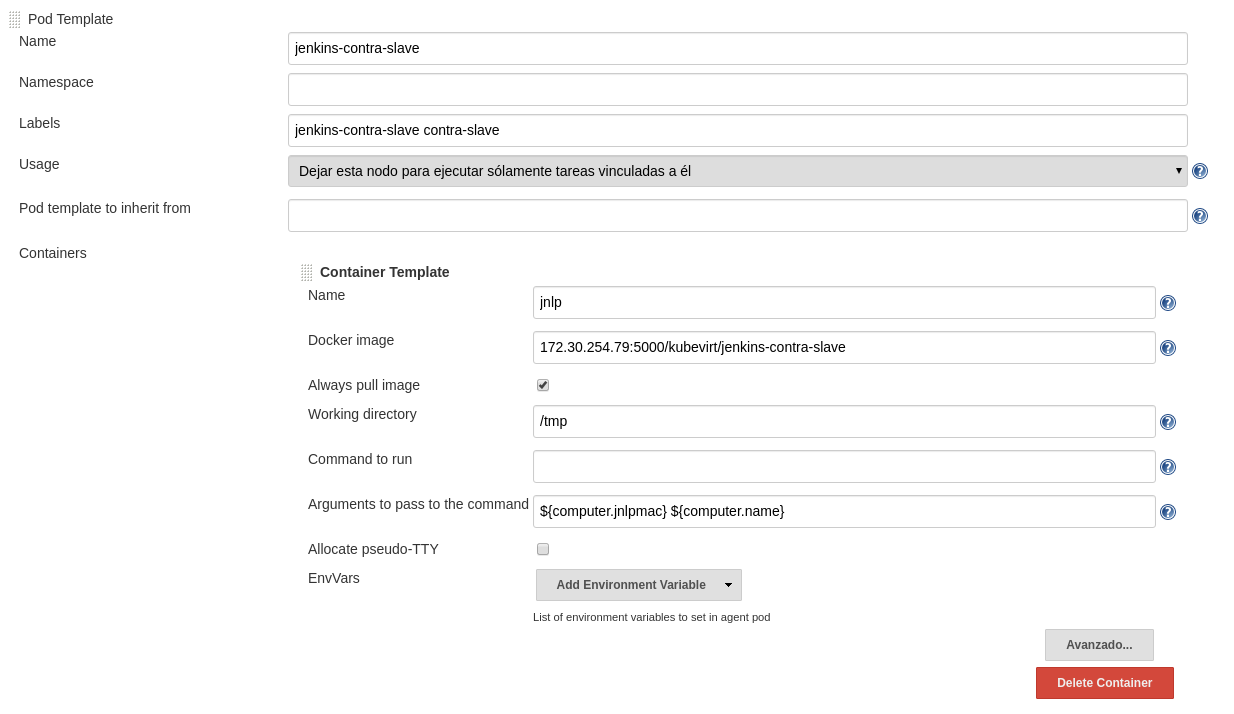
The libraries we added, automatically add some pod templates for jenkins-contra-slave:
Other changes
Our environment also used other helper tools as regular OpenShift builds (contra):
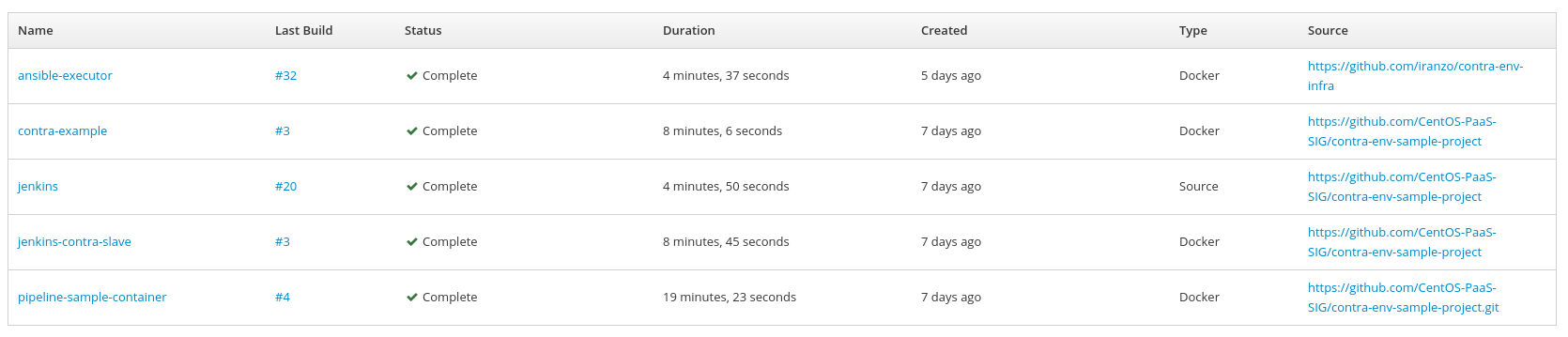
We had to update the repositories from using some older forks (no longer valid and outdated) to use the latest versions, and for the ansible-executor we also created a fork to use the newest libraries for accessing Google Cloud environment and tuning some other variables (https://github.com/CentOS-PaaS-SIG/contra-env-infra/pull/59) (changes have now landed the upstream repo).
The issue that we were facing was related with the failure to write temporary files to the $HOME folder for the user so ansible configuration was forced to use one in a temporary and writable folder.
Additionally, Google Cloud access required updating libraries for authentication that were failing as well, that is fixed via the Dockerfile that generated ansible-executor container image.
Job Changes
Our Jenkins Jobs were defined (as documented in prior article) inside each repository that made that part easy on one side, but also required some tuning and changes:
- We have disabled minikube validation as it was failing for both AWS and GCP unless using baremetal (so we’re wondering about using another approach here)
- We’ve added code to do the actual ‘Slack’ notification we mentioned above
- Extend the try/catch block to include a ‘finally’ to send the notifications
- Change the syntax for ‘artifacts’ as it was previously
ArchiveArtifactsand now it’s apostBuild
The outcome
After several attempts for fine-tuning the configuration, the builds started succeeding:

Of course, one of the advantages is that builds happen automatically every day or on code changes on the repositories.
There’s still room for improvement identified that will happen in next iterations:
- Find not needed running instances on Cloud providers for reducing the bills
- Trigger builds when new releases of KubeVirt happen (out of kubevirt/kubevirt repo)
- Unify testing on Prow instance
Of course, the builds can be failing for external reasons (like VM in cloud provider taking longer to start up and have SSH available, or the nested VM inside after importing, etc), but still a great help for checking if things are working as they should and of course, to get the validations improved for reduce the number of false positives.